Search engine crawlers (also known as spiders or bots) continuously look for and evaluate new and relevant online content available, by visiting millions of websites a day.
Various tactics are employed to ensure the inSided community platform is a technically hospitable environment, where crawlers can easily find their way and build powerful indexes that result in ranking and analyses.
Crawl budget
A crawler’s visit to any inSided community has to be both fast and effective, within the scope it has been given by its employing search engine. A so-called “crawl budget” is determined based on the domain’s reputation (rank) and limits the amount of time and requests a crawler can spend from any point of entrance. In other words, depending on how well a search engine values the community, its crawler can only see so much from the community before proceeding on to the next site. Guiding the crawler efficiently to the most valuable content is therefore important.
XML Sitemap
In the early days of search engines, XML sitemaps and “submitting content” in general were effective means of driving successful indexation and SERP ranking. Nowadays, search crawlers have become incredibly efficient and intelligent in casting an ever-wider content net, and do so around the clock, all on their own.
That being said, XML sitemaps can still serve a purpose for complex websites that have fresh content served in expected and less expected locations. Search engines like Google can be given a hand by pointing them directly towards each new item, the second after it’s published. It won’t guarantee such pages to be indexed, but it will help suggest the crawler to have a peek and assess their quality. XML sitemaps can therefore cause a slight increase in speed of indexation, rather than improve ranking, necessarily.
The inSided platform allows for the adding a sitemap to Google Search Console (formerly known as Google Webmaster Tools) by providing for automated RSS newsfeeds. You can locate your community’s feed by appending /feed/topics after the domain name, which then provides a valid and real-time XML sitemap feed of all recent topics. By doing this, you will give Google a competitive advantage with ever-fresh and user-generated content.
Representative statuses and redirects
Any thriving, dynamic website is from time to time affected by structural changes in content.
For example, topics created by users can be moved or deleted for a number of moderation motives. Any time this happens, the platform should clearly indicate how these changes should be interpreted, once a user or crawler tries to enter such an URL. This is done by returning the proper HTTP status codes for each misguided request. The crawler therefore always knows which entries to skip or update whenever it fails to locate content, without feeling bad about it.
According to Google, the top 5 error codes its crawlers encounter on the web are as follows.HTTP codeStatusExample cause
500
Internal server errorThe platform experiences temporary problems404
Not foundRequested topic has been deleted403
ForbiddenUser should login to access private topic400
Bad requestA browser problem involving cookies has occurred401
UnauthorizedInsufficient permissions to access pageIn other cases, users could be in need of a redirect. For example when following permalinks to posts, or to articles that have had their titles changed and got renewed URL’s. A platform response to such a request is accompanied by a 301 code (“moved permanently”) and a redirect instruction for the crawler to follow. This way, no content will mistakenly get lost.
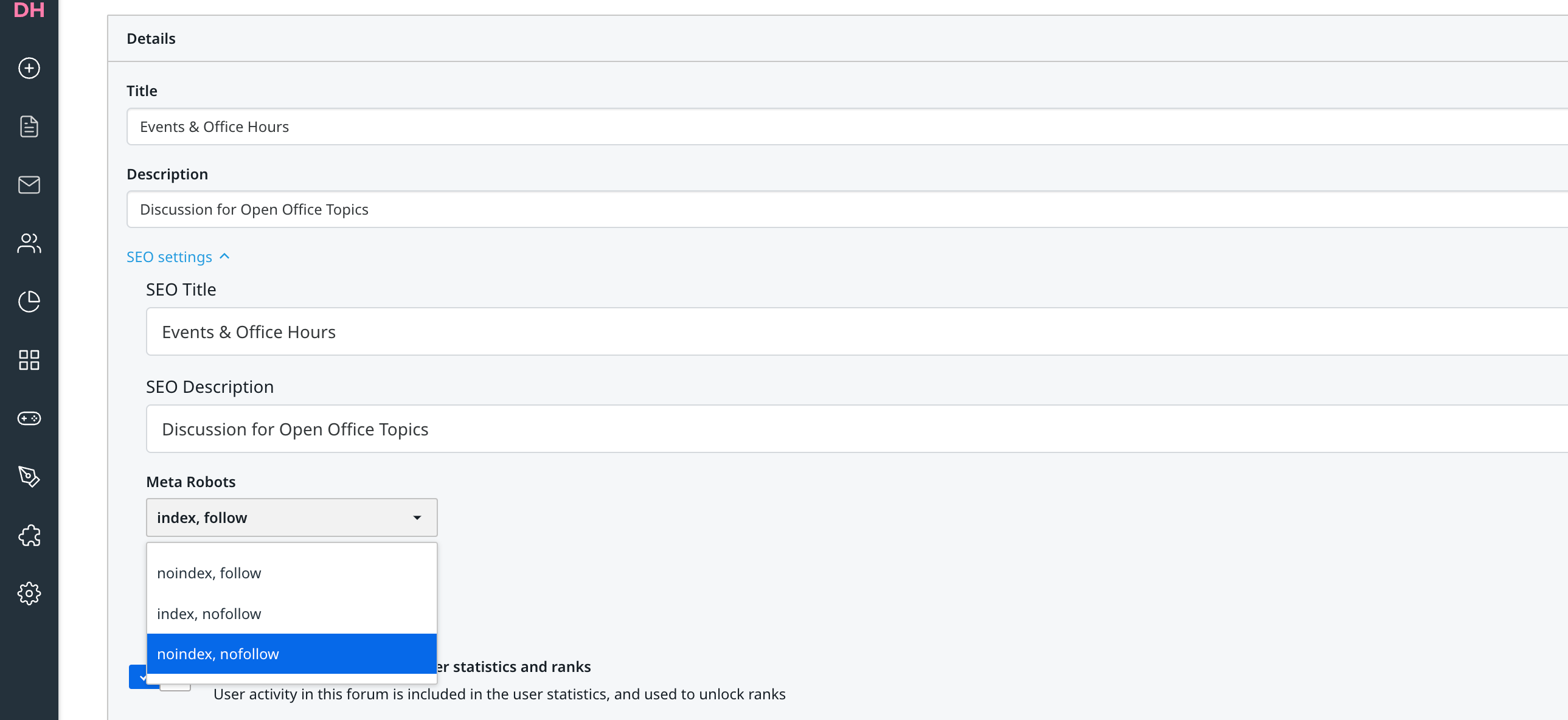
Excluding content from indexation
For clients that use branded templates to allow for automated and continuous community functionality updates, the platform cannot support excluding specific content from indexation by crawlers.
The reason for this is that, in the past, there have been experiments which applied noindex meta-tags and robots.txt techniques to exclude, for example, community search results and profile pages. While search engines tended to comply with these measures, we then could not find any significant influences on SERP ranking or increased organic traffic. Our advice is therefore to allow for full indexation of all public content and let our applied industry best practices in SEO techniques guide search engines to intuitively interpret the community platform.
Of course, closing down (sets of) category sets from public view is possible using the advanced primary and custom roles (permissions) system. This will channel content towards certain groups of community users and will effectively shut out access towards any lurking crawlers.
Canonical representation
Various parts of the community represent logical sets of data, such as category sets with topics, topics with posts and various search results. These sets are shown in lists that can be handled in various ways, for example browsed, sorted or filtered. While this serves a clear purpose for the user, crawlers need also to be able to make sense of these sets, in order to properly assess the data and refrain from handing out penalties for duplicate content. That’s why there are roughly two types of page behavior that need to be supported by so-called “canonical” link tags.
Once a shown lists exceed certain thresholds for amount of posts or topics, it will be split up into multiple pages in order to create a clear overview for the user. Because each single page has its own unique URL, canonical information helps a crawler to understand how a given page belongs within a set. It does this by identifying its optional previous and next pages, relative to its own position.
Several lists provide functionality which enable the user to interactively sort or filter content. Category sets, for example, allow for limiting the topics shown to only those which were active during the past month. This is achieved by creating a new page URL with an active parameter, such as “?range=month”. For a crawler, however, this new URL doesn’t make sense since it delivers the same content via another route. Providing canonical information, again, helps the crawler here by properly interpreting the content’s structure.
Note that canonical tags would not be used for redirecting traffic from specific topic pages to, for example, alternative community topics or campaign pages that would be deemed more attractive for online marketing reasons. Search engines would not allow for and recognize such inappropriate use, and shall probably assign ranking penalties if it’s tried. The inSided platform therefore doesn’t allow for this use case. Instead, we advise to use inline links within topic posts to direct attention to related quality content. For content that is assessed to be of no more value and is ought not to be found anymore, it’s probably best to either delete the topic or to move it towards a moderator-only category set, hidden from public sight.